
Introduction
Mining of linguistic associations is described here. On this page we describe program LAM which is a software realization of methods developed at our institute.
LAM
LAM is an experimental program developed at IRAFM. Its purpose is to implement and test ideas and algorithms connected to mining of linguistic associations and to mining of associations using F-transform. LAM is a small software utility for Windows platform. It uses LFLC libraries for working with fuzzy sets, evaluative expressions and linguistic descriptions.
We will show the function of LAM program on the Boston Housing dataset from StatLib library which is maintained at Carnegie Mellon University. The dataset concerned housing values in suburbs of Boston. The number of objects is 506 (without missing values). The total of 14 attributes were measured on each object such as nitric oxides concentration (parts per 10 million), weighted distances to five Boston employment centers in Boston region, full-value property - tax rate per $10,000, black proportion of population and other ones. We will present our results on the following attributes where X6 (RM) and Y (MEDV) is dependent, the other three attributes are regarded as independent:
- X1 (CRIM) - per capita crime rate by town
- X2 (ZN) - proportion of residential land zoned for lots over 25,000 square feets
- X5 (NOX) - nitric oxides concentration (parts per 10 million)
- X6 (RM) - average number of rooms per dwelling
- Y (MEDV) - housing value
First, user have to specify two input files. A file with the extension .dat contains data records and file with the extension .var contains description of variables. We select files housing.dat and gousing. var. On the righthand side of the GUI, various parameters can be set, e.g., parameters r and gamma, type of quantifier, range of evaluative linguistic expressions used, etc.
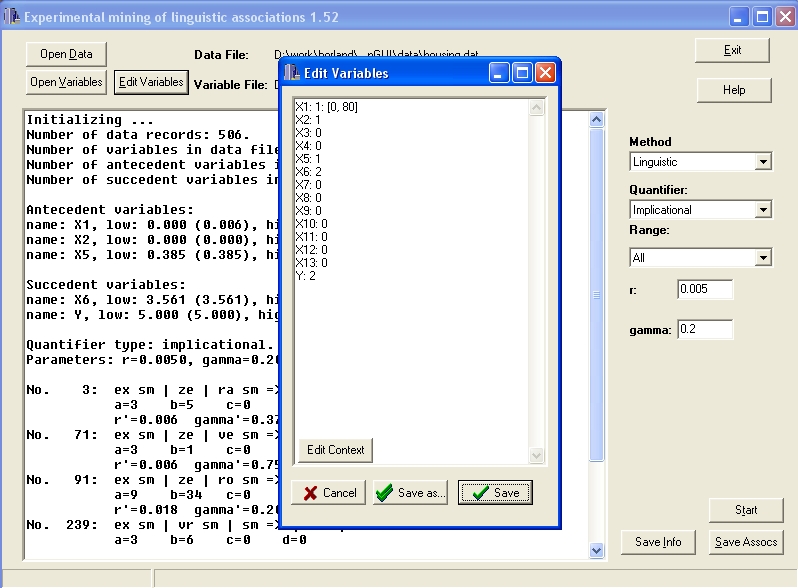
Using the "Edit variables" button, user can change which variables are trated as dependent and which as independent. Number 1 after the variable name means dependent variable, 2 means independent one, and 0 means that the corresponding variable will be ignored during the computation. It is also possible to determine lower and upper bounds of the scale of these variables. Any value greater than the upper bound is then treated as miximal, and, analogously, any value smaller then the lower bound is treated as minimal by LAM. These values are indicated in square brackets, in our case it is used for the X1 variable.
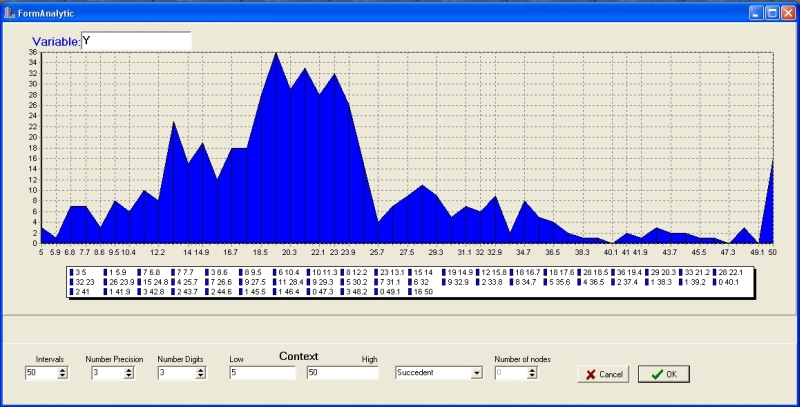
Using the "Edit context" button in the "Edit variables" window above, user can depict the distribution of data in individual variables. Lower and upper bounds mentioned above can be changed here as well.
After pressing the "Start" button, the computation starts, and messages and results are displayed in the main window.
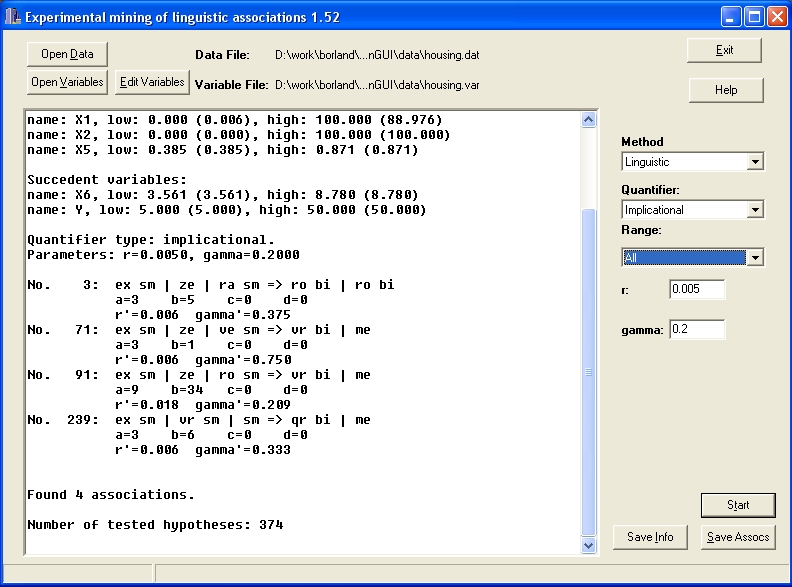
For example, the first found association can be interpreted as follows:
Extremely small per capita crime rate by town AND zero proportion of residential land zoned for lots over 25,000 square feets AND rather small nitric oxides concentration "imply" roughly big average number of rooms per dwelling AND roughly big housing value.
Found associations can be saved in the form of a set of fuzzy/linguistic IF-THEN rules by means of "Save assoc" button. These IF-THEN rules then can be loaded to LFLC software system. The "Save info" button permits to save messages about the course of computation and results as a text file.
Conclusion
We briefly introduced the LAM software tool. Information about methods of linguistic associations and further references can be found here.